


60 years of historical weather as free API and download
How we build a fast API based on 20 terabytes of open weather data

Tl;dr: Open-Meteo offers now historical weather data dating back to 1959! Open the API documentation to use the API or just download data as CSV or XLSX.
This was a long journey. Over the past decade I was working with environmental datasets. They have one thing in common: they are getting bigger and bigger.
With more than 20 terabytes of historical weather data, I dare calling it a “big data” challenge. Downloading, processing, compressing and encoding, took weeks.
Finally, a speedy historical weather API was built and I hope it simplifies the work of many students, academic researchers and journalists, because long historical time-series of weather data are difficult to find.

This post covers:
A brief overview of historical weather data
Where historical data is coming from
What the new historical weather API at Open-Meteo is
How it can be used and what the quality limitations are
How data is actually stored and made available through API
Brief overview of historical weather data
While working in the academic field, students often face the challenge of getting historical weather data for their research papers to analyse their hypothesis more deeply. With climate change and more extreme weather patterns, many journalists rely on measurements to objectively evaluate whether the current heat spell or drought is a new record high or “just weather”.
Often, the national weather services (NWS) are a good start as they operate high quality weather measurements stations over decades. Some NWS offer data on open-data servers in CSV or scientific data files. Other NWS do not even share data on request.
High quality weather stations measure weather according to WMO standards, others were just recently installed with commodity hardware and measure less reliantly with infrequent maintenance intervals. Quality, accuracy and reliability differs.
Even if you find weather station data for your country, odds are that there are no weather stations close to the location of interest or that the time-series data are incomplete or inconsistent. You can work around that, by combining data from multiple sources, filling gaps, ensuring consistency and using weather models to bridge larger distances between stations. Doing this, takes time.
Many researchers faced these issues in the past and started to work on “reanalysis“ weather datasets. The principle is:
Collect station measurements from the last decade
Combine them with satellite, radar and airplane observations
Grid data into 30x30 km cells
Use weather models to “fill in the gaps“
A reanalysis dataset can therefore provide global and consistent historical weather data bound by physical models. A reanalysis still depends on measurement data, but gaps and inconsistencies can be corrected more easily.

One of the most prestigious reanalysis datasets is ERA5 from the European Copernicus program in collaboration with ECMWF, which is also used for the Open-Meteo historical weather APIs.
ECMWF ERA5
ERA5 is the fifth reanalysis weather dataset from the publicly funded EU Copernicus program and implemented by ECMWF. ERA5 is available as open-data and you can download it from the Climate Data Store (CDS).
It offers global weather data in 30 km resolution and hourly values. There are literally hundreds of weather variables available and some of them on 137 atmospheric levels reaching 80 km altitude.
Data is available since 2019, but since June 2022 the real-time dataset is now available starting from 1959 until now with of delay 5-7 days.
By now, ERA5 is one of the most recognised historical weather datasets and used for many agriculture, energy and insurance applications.
Getting access to ERA5 is simple. Register an account, accept the license terms for open-data and with the CDS client Python library, you can start downloading. There is one drawback however: ERA5 is huge!
I did not find exact numbers, but the data size must exceed 1 petabyte (1024 terabytes). Even if you are only interested in a hand full of weather variables like temperature, precipitation and wind, you quickly have to download 1 terabyte or more. In the case of Open-Meteo with 23 weather variables, more than 20 terabytes had to be downloaded from the CDS. And this data were already compressed!
Working with this amount of data quickly turns into a computer science exercise and it is a pain for any researcher who only need time-series data for a couple of locations.
A new historical weather API
“Historical weather APIs” already exist. Some commercial weather providers offer historical data based on weather models or station measurements. Most of them are only offered at their most expensive “top-tier” commercial offers and the data source is not immediately clear.
To bridge the gap between a commercial offer and spending weeks downloading ERA5, Open-Meteo now offers a free (for non-commercial use) API for ERA5.
The new historical weather API works exactly like the Open-Meteo Forecast API, but you have to specify a start and end date. You can straight select the full time interval starting from the first of January 1959 until now.
Fetching data might take a while. Especially the first call to the API requires a couple of seconds for full 60 years of data. The API response in JSON format is more than 8 MB.
Consecutive calls to the API are quicker, because multiple disk accesses for the same data are cached. A bit on performance later.

With the integrated chart, you can quickly explore data, zoom-in and look at data into more detail. Or alternatively hit “Download XLSX“ and continue your analysis in a spreadsheet application.
Data are available globally for any land surface, with the exception of Antarctica and far North locations. This limitation was necessary to keep the required storage requirements lower.
A disclaimer about data quality
Although this data is based on measurements and enhanced with weather models, there are still significant differences to local measurements.
First of all, the historical weather APIs use gridded data with 30 kilometre resolution and therefore cannot represent very small scale patterns in temperature, winds or precipitation. Even measurements stations less than 100 meter apart, measure different temperatures.
Thunderstorms with convective precipitation (showers) are very local and the amount of rain differs within just a couple of kilometres. However, large scale patterns like country wide droughts are fairly well captured. Extreme events like individual heat records may also be incorrect, but the overall trend of rising temperature is well visible.
If you want to use this data for your own analysis, keep an eye open for potential deviations from actual local measurements.
How data are stored and made available through API
Working with vast amounts of data is not trivial. Even though only 23 weather variables from ERA5 are used, more than 20 terabytes are downloaded from the Climate Data Store (CDS).
To better understand why ERA5 requires that much data storage, lets to through the numbers:
ERA5 is using a regularly spaced grid of 0.25° in latitude and longitude dimension (approximately 30x30 km boxes). As an image it takes 1440 x 721 (roughly 1 million) pixel.
To store one day with 24 hours as 4-byte floating point number, 95 megabytes are required.
With 23 weather variables we already reach 2.1 gigabytes
365 days = 766.5 gigabytes
And with 62 years starting from 1959, we end up with 47 terabytes
47 terabytes sound impressive and is definitely the first number for every commercial product landing page. However, there is data compression.
Luckily, the CDS API already uses compression (NetCDF with deflate) to reduce the required space by half.
Instead of 2.1 gigabytes, with compression we get roughly 1 gigabyte per day
With 62 years, ~22 terabytes
Needless to say, a typical computer is not equipped to store this amount of data and to work on this dataset I improvised my workstation at home.
To get around 50 terabytes of usable store, I use the filesystem ZFS to combine a couple of large hard-disks. Additionally ZFS ensures data integrity with checksums. Most hard disks have an error rating of 1 bit-error every 12 terabytes. It is almost certain that there will be at least 1 bit-error in the downloaded ERA5 dataset.

At this point, an API is still very far away. To access a continuous time-series from the downloaded dataset, all data have to be decompressed to read one single location.
Because the API returns data for only one location per call, instead of storing spatial images of ERA5, we rotate dimensions to store time-series and then compress each time series individually. If the API reads the temperature series for Berlin in Germany, it only has to decompress a small subset. With many file formats like zarr or NetCDF this can be done easily (“chunked dimensions“ in NetCDF).
Unfortunately, compression is not great. Some tricks can improve compression with NetCDF:
Instead of storing full floating point accuracy to temperature, it can be scaled by factor 20 and then stored as integer. Accuracy would be reduced to 0.05°C, but this is more than enough.
Because temperature is slowly rising or falling, it is possible to store just the “delta” to the previous time step. Resulting numbers get smaller and repeat more often, which then increases compression.
Using long time series, scaling and delta-coding improves compression by a factor of 2. Instead of 22 terabytes, roughly 10 terabytes are required.
With 10 terabytes, this is still far from ideal and running a simple API is challenging because of this size. Just to store this amount of data with Amazon S3 costs 250$ per month and this is plain storage.
Modern compression algorithms like Zstd, Brotli or lz4 perform slighly better (~20 %) than the default deflate algorithm in the NetCDF data format, but are not directly available.
Because weather is slowly changing and delta-coding keeps values very small, an integer compression algorithm Patched Frame of Reference (PFOR) can be used. It works astonishingly well and reduces the size even further to 6 terabytes.
Another important property of weather data is spatial coherence. A temperature map shows similar values for large areas. If you compare neighbouring locations, the temperature data is almost the same. Often less than 0.5°C.
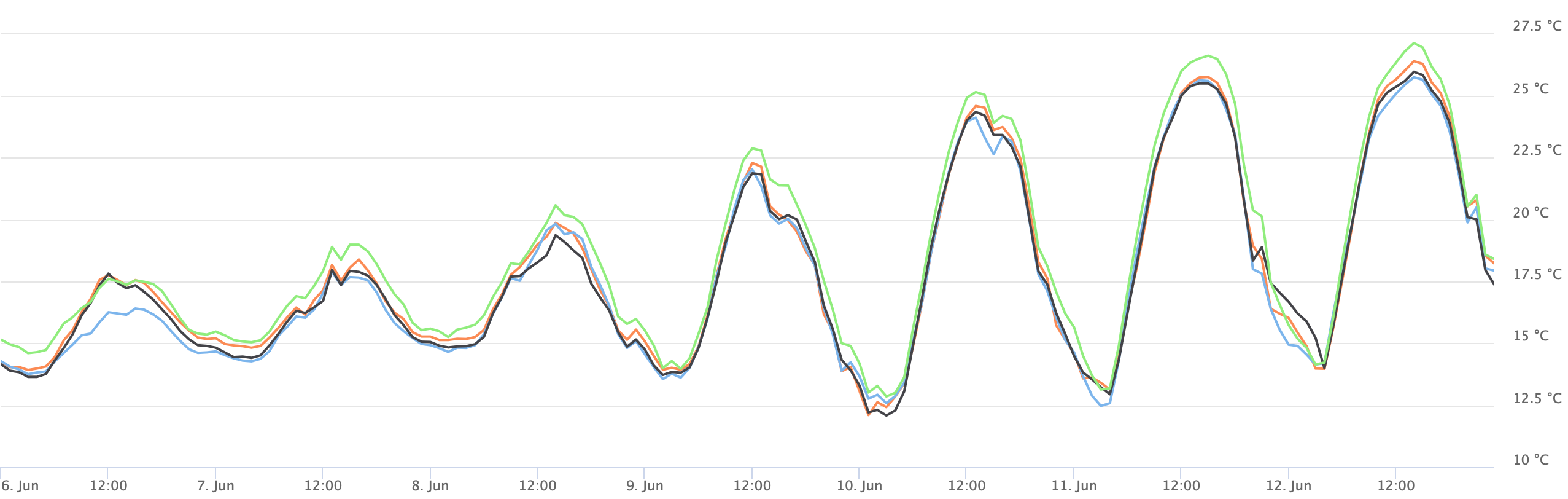
Similar to the delta-coding for time series data, the delta of 3x3 (9) neighbouring locations can be calculated. Using multi-dimensional delta-coding pushes storage size even further down to just shy of 4 terabytes.
As a last resort to get it even smaller, less popular used regions can be removed. In this case, all ERA5 data from sea, Antarctica and very remote northern locations, are removed. This step is rather drastic, but with only 1.2 terabytes remaining, it is now a manageable size for an API. If there is larger interest, an unconstrained version could also be provided.
As a final step, ERA5 is now integrated into the same source code as the Open-Meteo weather forecast API with the same API syntax, format and documentation to make it easy to use.
All those layers of compression, scaling, delta-coding and chunking have considerable performance impacts. The final API performs quite well and is limited mostly by the speed of hard-drives. An uncached read for 62 years of weather data might even take a couple of seconds. Consecutive calls are typically below 10 milliseconds. As only disk accesses are cached and not the entire JSON result, 10 milliseconds is the total time to decompress and decode data.
Compressing 47 terabytes down to 1.2 terabytes is a nice challenge and has hopefully practical use for data scientists looking for time series weather data.
There are plenty of new weather dataset that will be integrated in the coming month. The EU Copernicus program is a great source and soon work starts on 6 months seasonal forecasts and air quality data.
You can subscribe for free to this blog, to get the latest updates!
Hi everyone,
I'm looking for a dataset of EUROPE for selected sites at multiple heights from 70,80,90,100,110,120m from 2019 to 2024.
Is anyone help me get this?
First of all, impressive work! Also enjoying the blog posts, I'm learning a lot about weather and forecasting 👌 Thinking about using this in my next project
I'm still curious about how you serve the data. Specifically:
- about caching, I've been looking at the code base and haven't found anything specific about this. When you talk about caching, you mean the API uses the filesystem caching under the hood, right? Did you have to make any tweaks to improve performance?
- about the db itself, I've read it is a custom filesystem based data base. If I didn't understood bad, data is stored as compressed plain binary and, when a request comes in, it gets decompressed, and formated. Lets say I want to fetch data in a specific time range or apply some filters, how are those kind of operations performed?
Thanks for your time in advance!