
How to store weather forecast data for fast time-series APIs
Using multi-dimensional gridded files and time-series data-structures

In this post, I am explaining how Open-Meteo APIs store numerical weather-model data for fast access. I will briefly explain:
Basics of geographical grids
What weather-model runs are
Show different storage approaches for gridded data
How efficient weather forecast APIs can be designed
Chapter 1: Grids
Weather-models store data in grids with columns for east-west direction and rows for north-south direction. With 1000 columns and 1000 rows you would get 1 million grid-cells. With an earth circumference of around 40.000 km, each grid-cell is around 40 x 40 km in size.

To get the weather forecast for your location, the closest grid-cell is located and data returned. For users in the east of the US this might be grid-cell “C5“. It is very similar to an spread-sheet filled with temperature values.
Grids do not need to be global. Local higher resolution grids for smaller areas are common as well. In any case, grids are structured and the geographical coordinates for grid-cells can be calculated.
Depending on the resolution and size of your grid, the number of grid-cells can be huge. Open-Meteo uses grids with more than 4 million grid-cells. If you would store the values of this grid on your hard disk, the gridded file is 15 MB large using 32 bit floating point numbers.
Unfortunately, many of those gridded files are required. 7 days of hourly weather forecast require 168 files for each time-step. Just for one weather variable (e.g. temperature) it adds up to 2.5 GB.
At Open-Meteo, we use 35 weather variables like wind-speed, direction, relative humidity, pressure, weather-code, clouds, precipitation or snow height. Some weather variables are also stored for different altitudes like wind speed on 10, 80, 120 and 180 meters above ground.
In total, every single weather-model-run has to store around 87.5 GB of data.
4 million grid-cells * 32-bit * 168 hours * 35 variables = 87.5 GBWith today’s storage options on large hard disks and faster solid state disks (SSD) this is not inherently an issue anymore. On a 16 TB hard disk you could store 180 weather model runs. With 4 runs a day, this would be 45 days of archived data.
For now, this ignores compression and smaller data types than 32-bit floating points, but more on that later.
Chapter 2: Model-Runs
I briefly mentioned the term “model-run”. Weather-models are constantly updated with newest measurements, satellite & radar observations and airplane data. Nowadays every 3-hours weather models are started.
At 0:00 UTC time, all measurements are collected, assembled onto a grid and then numerical weather prediction equations are run to predict how air mass change, clouds form and the sun is creating convection.
After a couple of hours, the “run” finishes and can be downloaded. This run is referred as 0z run. The same procedure is repeated at 3:00 UTC with the 3z, 6:00 UTC with 6z and so on.

Every model-run overlaps with previous runs, but offers more recent data, improved forecasts and reaches a bit more into the future.
To save space, only the latest 2 runs could be stored. This can be observed with many weather forecast APIs. It is noticeable, because after the latest run, older data is not accessible anymore. For example, API calls for today’s data, return only data after 9:00 UTC time, not no information about the night anymore.
Another common solution (and also how Open-Meteo does it), is to merge multiple model-runs. Newer runs overwrite portions of older runs, but leave previous data.
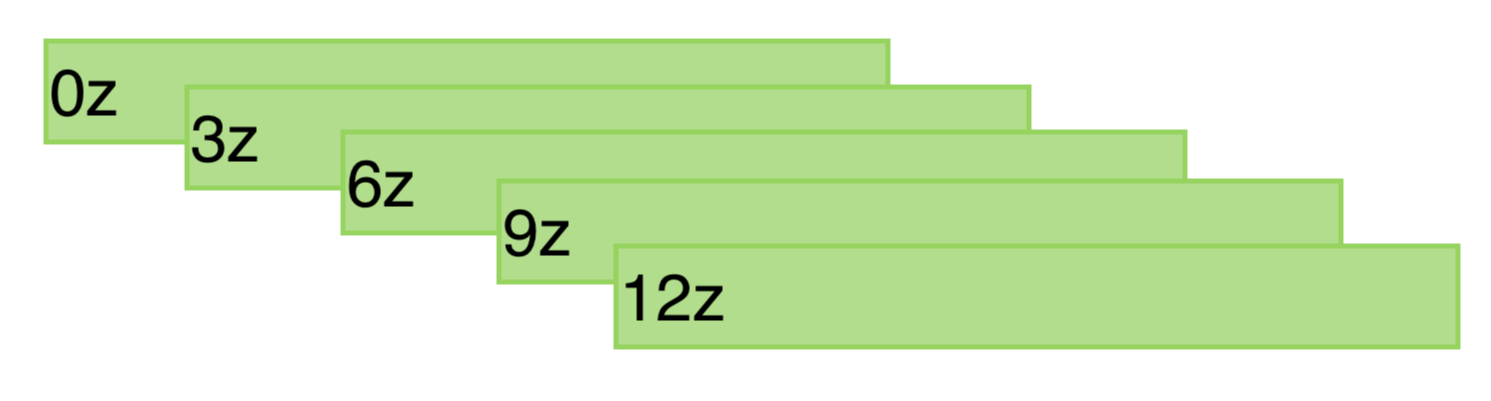
A drawback of this technique are data-inconsistencies like sudden jumps in temperature or sunny weather switching to pouring rain. With rapid updating weather-models every 3 hours, this is more rare.
Chapter 3: Reading data from gridded files
There are two use-cases for reading data:
Create a weather-map for one timestamp
Get an hourly time-series for one location
The first use-case works quite well. With gridded data files, only one file has to be opened and the entire global data for one timestamp can be read straight away. In essence, gridded data files are a “picture” of the entire world.
The second use-case for time-series data is not optimal. Every timestamp is in a different gridded-file. For 7 days (168 hours), 168 files have to be opened and a single value read. 10 weather variables have to read 1680 values from 1680 files.
On fast SSDs every open-file and read operation takes a fraction of a millisecond, but it multiplies by 1680. With half a millisecond for each read operation, this results in almost 1 second of waiting time. For an API, this is eternity.
In practice, it can be optimised by keeping files open or using caches to make is faster. It is possible run an API with less than 100 millisecond response time, but it is far from ideal.
Chapter 4: Using a relational database
Many weather APIs store weather-model data in database management systems like MySQL, PostgreSQL or SQLite.
The solution comes naturally and looks straight forward. A simple table with columns:
Timestamp
Latitude
Longitude
Temperature
Wind speed, direction, relative humidity, …
Additionally, some indices need to be defined on latitude, longitude and timestamp to access all timestamps quickly.
The database management system keeps data compact on disk. For each row, all weather variables are stored together. E.g. Bytes for temperature and wind-speed are next to each other.
time,lat,lon,temperature,windspeed,direction,humidity,…
To read data, the database management system has to traverse the indices for a given geographic location (latitude and longitude) and retrieve data for all timestamps. All weather variables are local and reading temperature, wind speed, direction and other variables all at once is quick.
Reading times are good with 50 milliseconds or less.
Unfortunately, there are a couple of drawbacks:
Storage overhead: For each row, timestamp and geographic coordinates have to be stored again. In gridded files, this is not required, because you know the dimensions of each grid-cell.
Indices memory: To find the correct locations and timestamps quickly, large indices are required which consume multiple GB memory.
Updates: For every weather model-run large portions of the database have to be rewritten. In practice this is a huge issue. Updates take an hourly or more and performance drops significantly.
Scaling: To improve performance more nodes are required and data has to be clustered. It works for small data-sets, but scaling becomes expensive.
Relational databases are not built for gridded data. Properties like spatial context are lost and operations become unnecessarily complex.
Chapter 5: Time-series in gridded files
Gridded data is not limited to 2 dimensions for east-west and north-south. A third dimension like “time” is an option.
The 1000 by 1000 grid in chapter 1 could be expanded with the third dimension “time” and a cardinality of 168 hours to fit our 7 day weather forecast. Dimensions would then be: east-west (1000), north-west (1000) and time (168).
The order of dimensions is important. In one case 168 “global pictures” are stored one after another. In the other, 1 million time-series of each 168 hours are stored. Naturally for a time-series API we need the later case.
On disk every grid-cell stores 168 hours of data, immediately followed by the next 168 hours for the next grid-cell.

Reading a single 168 hour weather-forecast for temperature, is now a single and a quick read operation.
With each model-run these files can be generated easily. There is not much difference of generating different gridded files for each time-step or 3-dimensional files of all time-steps at once.
Multiple weather-models-runs still need to be considered and providing data for the entire current day, we have to read the latest 4 or 6 runs. This issue of merging multiple runs into just one time-series is explained in the next chapter.
Chapter 6: Time-series data
If we look back at how multiple model-runs can be overlaid together, it becomes apparent that data can be constantly updated in the same file thus creating a time-series.

Subsequent runs can overwrite portions of older data as well. With more and more runs, all data will be overwritten at some point.
At Open-Meteo the each time-series file stores roughly 10 days of data. Every 3 hours new weather-model-runs finish and will be integrated into this time-series structure.
Doing updates in-place (e.g. modifying the existing files) simplifies data handling a lot. Otherwise, you would have to keep many duplicates files for each model-run.
It has also more practical advantages, because file-systems have to manage files on actual hard-disks. If the files always maintain the same size and reside at exactly the same location on disk, there is not much work to do. Updates basically rewrite the modify entire file and nothing else.
Data on disk is stored in blocks of 512 or 4096 bytes. Nowadays 4096 bytes are more common with fast SSD storage. A single 1 byte modification has to read 4096 bytes, modify one byte and then write 4096 bytes again to disk. Because the most disk workload is written in larger sequential blocks, this is barely noticeable.
For larger time-series-sizes like 100 days, 9600 bytes are required for one grid-cell using 32 bit floating point numbers. Although only 7 days (672 bytes) are updated with every model-run, the operating system has to read, modify and write the entire file.
4 million grid-cells * 32-bit * 100 days * 24 hours = 35.8 GBOne time-series file for one weather variable is 35.8 GB or 1.25 TB for all 35 weather variables. Updating 1.25 TB of data every 3 hours is manageable, but has larger impacts on system load.
With compression, this can be reduced. In the blog post about 60 years of weather history, it is explained in further detail.

A single time-series can be read with one operation in less than 0.1 milliseconds. For 10 weather variables, APIs with latencies below 1 milliseconds are feasible.
Compared with regular gridded files:
Time-series gridded files only have to open one file and do one single read, because all time-series data is sequential
Compared with relational databases:
No indices are required
No operational burden on clustering data is required
APIs can be scaled by copying files to more servers
Chapter 7: Kernel page cache, memory mapped files and non-blocking IO
There are some tweaks to make it even faster and more efficient. I will just give a short overview of those techniques without a deep give into Linux kernel fundamentals.
First the Linux page cache keeps commonly read data in memory. Forecast data in densely populated areas are likely already in the page cache. Consecutive API calls that get the same data are significantly faster.
The page cache transparently caches files on local file systems. Times-series-based gridded files do not have to reside on local file-systems only, but could use shared or remote file-systems like Amazon Elastic Filesystem (EFS) or Cephfs. In later posts I will explain how to use distributed file systems to store gridded data in conjunction with fast APIs.
To get the most out of the page cache, Open-Meteo also uses “memory mapped files (mmap)”. A gridded file is transparently mapped into memory and behaves like one large floating point array. In the previous example, it would be a floating point array with almost one billion elements. Memory mapped files are not read entirely into memory, but on access will read data from disk. If data already reside in memory, no reads are required. In the worst case, every read performs a read from disk.
Finally, reading data from multiple files can be done in parallel. This requires multi-threaded code or asynchronous event-loops to achieve non-blocking IO. With memory mapped files there is an alternative way. To read 10 weather variables at once, we tell the Linux kernel which 10 data regions we need and the kernel starts preparing reading data for all 10 weather variables. By the time data is accessed, they are hopefully present in the page cache. Technically, this is still blocking IO, but multiple parallel reads are performed in the background. Using this technique cuts down API latency by half.
Additionally to save space, many weather variables also use 16-bit floating points with less precision, but require only half the space.
Chapter 8: Conclusion
The end-result are API reading-times of 2 milliseconds for 10 weather variables and 0.4 milliseconds for consecutive calls.
Additional features, like combining high-resolution weather models, derived weather variables and down-scaling techniques also add latency. Areas covered with 3 weather models, take 6 milliseconds to read and 0.5 milliseconds for consecutive API calls.
With low API latencies the operational cost for API services can be kept very low. Open-Meteo is (and will be) free for non-commercial use without API key limitations. This can only be achieved with efficient data storage and APIs.
Time-series-based gridded files are a key ingredient to efficiently store and update weather-model data and be able to quickly retrieve forecasts for single geographical points.
For longer time-series and archives, different techniques have to be used that focus on compression and support large distributed storages to be cost effective.
In later posts, I will explain how to design systems for a time-series weather archive, how different how high-resolution weather-models can be combined with low-resolution models or how weather variables can be computed on demand.
To get latest updates, via mail, you can subscribe to the Open-Meteo blog for free:
Otherwise, I encourage everyone to use Open-Meteo APIs and build Open-Source tools to work with weather data. If you have questions, idea, feedback or suggestions, please comment below.
Thank you for the great open-meteo work.
Can you tell me where I can get more detailed, exactly technical information on storage of weather and archive data in the form of time series? How it is organized in details. Do you use your own structures or are they based on other research. Thanks