
Historical Weather API with high resolution data
Global data with resolutions of up to 5 km for up to 60 years

I am pleased to announce an exciting upgrade to our historical weather API. For the first time, we are now offering data with a resolution of up to 5 km. This high-resolution data will provide users with an unprecedented level of detail and accuracy, making it an invaluable resource for a wide range of applications.
The initial version of our historical weather API used data with a resolution of 25 km, which already required us to overcome a number of technical challenges. The sheer amount of data was enormous, and we had to implement specialized compression techniques and remove data for locations in the ocean in order to keep it manageable.
The latest upgrade to the historical weather API now makes data available globally, with a resolution of 11 km for locations on land and an even higher resolution of 5 km for locations in Europe. This increase in data has presented new challenges in order to maintain the fast performance of the API.
As always, our historical weather API is available for free for non-commercial use, with comprehensive documentation of all available weather variables. It is also easy to use, with simple CSV and XLSX downloads available.
This post covers the addition of new weather reanalysis datasets to our API and addresses new technical challenges we faced in order to compress and store the data.
Tl;dr:
Historical weather data is now available for locations in the ocean as well as globally on land
Up to 11 km resolution (previously 25 km) for surface weather variables
Up to 5 km resolution for Europe, but only until June 2021
Weather Reanalysis
he Historical Weather API is based on reanalysis datasets and uses a combination of weather station, aircraft, buoy, radar, and satellite observations to create a comprehensive record of past weather conditions. These datasets are able to fill in gaps by using mathematical models to estimate the values of various weather variables. As a result, reanalysis datasets are able to provide detailed historical weather information for locations that may not have had weather stations nearby, such as rural areas or the open ocean.
The process of combining weather measurements, known as assimilation, is similar to that used in weather forecasting models. However, because reanalysis datasets are not required to be calculated as quickly as weather forecasts, they have more time to incorporate measurements from a wider range of sources. This allows for a more comprehensive and accurate representation of the state of the atmosphere over a specific period of time.
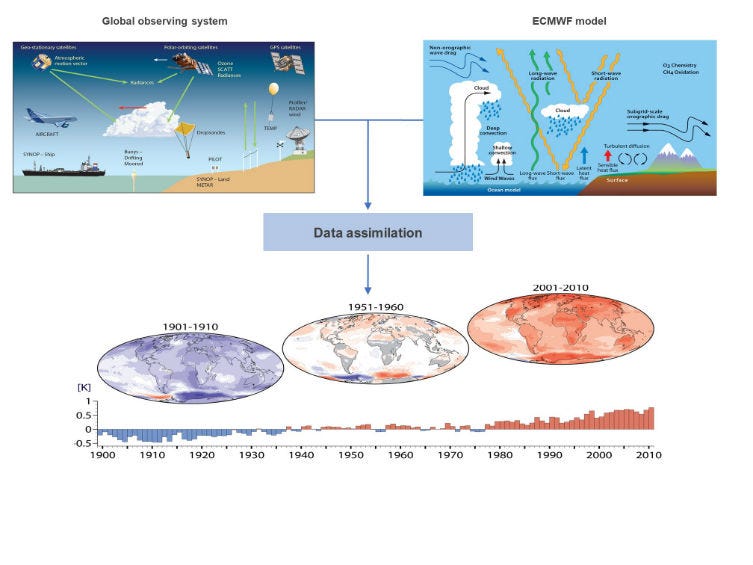
The spatial resolution of a weather reanalysis dataset refers to the size of the grid cells used to represent the data. The initial reanalysis dataset, ERA5, used a resolution of 25 km, which could be limiting in terms of accuracy, particularly in coastal areas and in mountainous regions. In general, a higher spatial resolution means that the data is more detailed and represents the weather conditions more accurately at smaller scales.
Our newly added datasets, ERA5-Land (11 km) and CERRA (5 km), significantly improve upon this limitation by offering higher spatial resolutions.
ERA5-Land
The ERA5-Land dataset uses the same assimilated data as the ERA5 dataset, but at a higher resolution. This higher resolution is computationally expensive, so only certain surface weather variables are calculated at this resolution, such as temperature, humidity, soil temperature, and soil moisture. Other variables, such as precipitation, wind, and solar radiation, are instead estimated using a simple interpolation method rather than expensive numerical modeling. This allows the ERA5-Land dataset to offer a high level of detail and accuracy for certain variables while still being computationally efficient.
The native grid resolution for the ERA5-Land dataset is 9 km, but the resulting grid is spaced by 0.1°, which is approximately equivalent to 11 km. This dataset includes data from 1950 with hourly resolution.
The ERA5-Land dataset was released a few years ago, but updates were infrequent and often delayed by several months. With the release of real-time updates in December 2022, the delay has been reduced to just 5 days, bringing it on par with the ERA5 dataset.
As soon as the real-time updates were announced, I began working on integrating them into Open-Meteo. ERA5-Land is available as open data through the Copernicus program's Climate Data Store (CDS), but downloading it can take weeks and requires a large amount of storage space. To make it more accessible, the Open-Meteo Historical Weather API now allows users to easily download data for individual locations with just a few clicks.
By default, the API combines ERA5-Land and ERA5 seamlessly, but users can also choose to use one dataset or the other individually. Not all weather variables are now available from ERA5-Land, but the API will automatically use regular ERA5 data if it is not available from ERA5-Land. The chart below illustrates a direct comparison between the two datasets.

CERRA
As the resolution of weather reanalysis datasets increases, the challenges involved in creating and managing them also increase. The Copernicus European Regional ReAnalysis (CERRA) is a new reanalysis dataset that is limited to Europe and has a resolution of 5 km.

Like ERA5-Land, the CERRA dataset is based on the 25 km ERA5 reanalysis dataset. CERRA also offers all weather variables for both surface and atmospheric levels, providing a significant improvement in variables such as precipitation, solar radiation, and clouds.
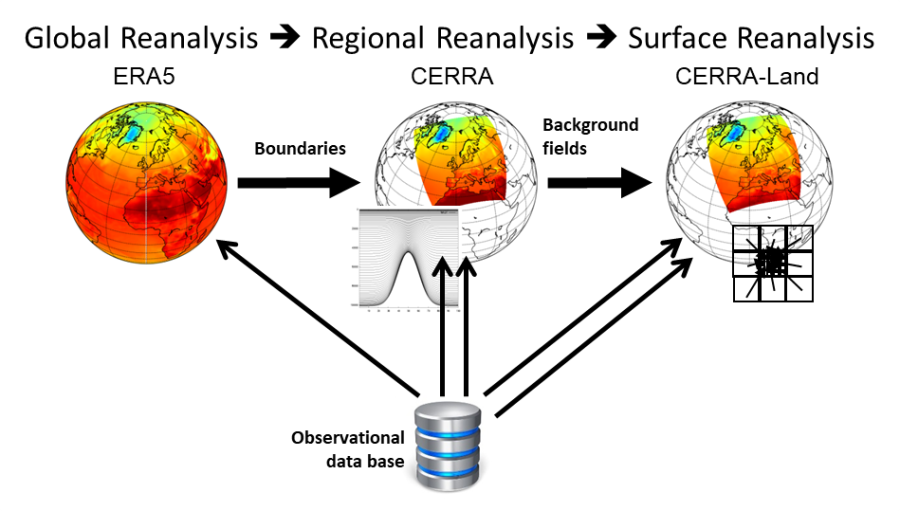
The CERRA dataset is relatively new and was made widely available in October 2022. At present, it does not offer real-time updates and the data is only available until June 2021. However, the European Centre for Medium-Range Weather Forecasts (ECMWF) is working on providing real-time updates for CERRA sometime in 2023. This will make the data more current and allow users to access the most up-to-date information possible.
CERRA is now also available through the Open-Meteo Historical Weather API. However, as it does not currently have real-time updates, it will not be automatically used in the API. Users can choose to use CERRA individually or compare it to the ERA5 and ERA5-Land datasets (as shown in the graph below) by selecting it from the list of available reanalysis models.

With the availability of three weather reanalysis models at different resolution, it is interesting to compare them next to each other. In the graph above, data for Berlin, Germany is compared and it can be seen that CERRA shows particularly higher daytime temperatures. This illustrates how higher resolution data is able to better represent local effects.
Data management
As the volume of data available through the Open-Meteo Historical Weather API has increased, it has become more challenging to store and manage it all. While it is possible to purchase large hard drives with capacities of 20 terabytes or more for a relatively low price, running an API service is a different matter. Many users may want to access the data simultaneously, requiring fast access times that can only be provided by solid state disks (SSDs).
In a previous blog post (linked below), I explained how I was able to compress the ERA5 dataset from 47 terabytes down to 1.2 terabytes. While 1.2 terabytes is still a significant amount of data, it is manageable on a single server. However, the monthly cost for a single server on Amazon Web Services would be $120.00, making it important to consider the cost-effectiveness of different storage solutions.

It is clear that adding two additional weather reanalysis datasets will significantly increase the amount of data storage required. In addition, I also want to make the entire ERA5 dataset available, without excluding locations in the ocean.
Yet another time, I booted up my local workstation, attached 10 hard disks and started downloading ERA5-Land and CERRA. Data have been downloaded from the Climate Data Store (CDS) as compressed GRIB files. Despite being compressed, the raw data amount is still large.
ERA5: 1 month = 30 gigabytes, 62 years = 22 terabytes
ERA5-Land: 1 month = 35 gigabytes, 62 years = 26 terabytes
CERRA: 1 month = 23.8 gigabytes, 37 years = 10 terabytes
Total: 58 terabytes
To store the data in an efficient format, I again used specialized compression algorithms, chunking, and multi-dimensional delta coding. These techniques allowed me to reduce the file size by a factor of 5 compared to regular GRIB compression. Resulting in:
ERA5 with ocean locations: 4.2 terabytes
ERA5-Land: 2.8 terabytes
CERRA: 2.3 terabytes
Total: 9.3 terabytes
Well…. 9.3 terabytes on SSDs costs $760.00 per month on AWS. Not doing to happen. Instead, I rented a dedicated server with 2x 16 terabytes hard disks and 2x 500 gigabytes speedy SSDs for less than $100 per month.
If I were to use only traditional magnetic hard disks to store the data, the performance of the Open-Meteo Historical Weather API would be poor. These types of disks can take up to 10-20 milliseconds to read a random block of data, while the API typically takes only 1-10 milliseconds to generate a historical data record for one year and multiple weather variables at once. This demonstrates the importance of using SSDs.
Although the size of the entire historical weather database is 9.3 terabytes, only a small fraction of the data is frequently accessed. For example, data for locations in the ocean may never be requested by any users. In these cases, waiting an additional 200 milliseconds for data to be retrieved is tolerable.
To address this issue, I have used the open-source filesystem ZFS, which allows me to use multiple hard drives in redundant mode and utilise fast SSDs to cache frequently used data. Not only does ZFS ensure that the data has not been corrupted, it also combines the large storage capacity of hard drives with the fast access times of SSDs, making it an ideal solution for storing and managing large weather archives.
The new setup appears to be performing well, with even faster API times than before. There is also some additional capacity available for adding additional reanalysis datasets to Open-Meteo. I am keeping an eye out for any new datasets that may be suitable for inclusion in the future.
Conclusion
The updates to the Open-Meteo Historical Weather API have greatly improved its performance and make it well-suited for a wide range of use cases involving historical weather data. I am excited to be able to include real-time updates for CERRA in the future, and hope that more reanalysis datasets become available.
In addition, the Open-Meteo project is available as open-source on GitHub, and I encourage anyone interested to use the provided Docker images to set up their own weather APIs or even start downloading reanalysis datasets for their own purposes. The project is designed to be accessible and easy to use, so don't hesitate to give it a try!
To stay informed about the latest updates to the Open-Meteo weather APIs and other related news, be sure to subscribe to the Open-Meteo newsletter:
Really nice, increased resolution is a huge improvement!